 집
집  항해
항해




Deepseek의 새로운 챗봇은 대담하게 말했습니다. 이 소개는 주목을 끌었을뿐만 아니라 Nvidia의 가장 큰 주가 하락 중 하나에 기여하여 Deepseek의 시장에 미치는 영향을 보여주었습니다.
 이미지 : ensigame.com
이미지 : ensigame.com
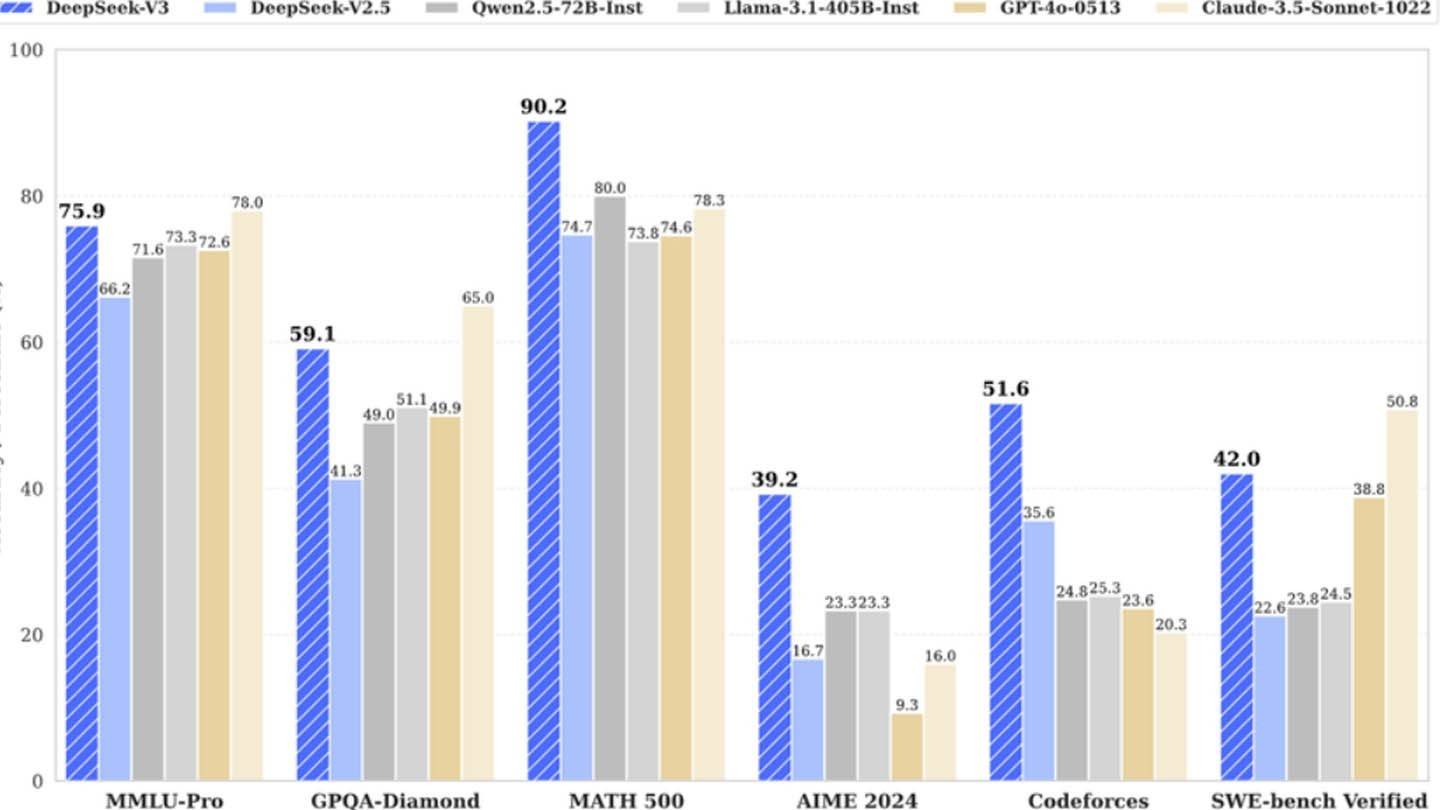
DeepSeek의 AI 모델은 혁신적인 아키텍처 및 교육 방법으로 인해 두드러집니다. 그것을 구별하는 주요 기술을 탐구합시다.
MTP (Multi-Token Prediction) :이 방법을 사용하면 모델이 문장의 다른 세그먼트를 분석하여 여러 단어를 한 번에 예측할 수 있습니다. 이는 정확도를 높일뿐만 아니라 모델의 효율성을 향상시켜 텍스트를 이해하고 생성하는 강력한 도구입니다.
전문가 (MOE)의 혼합 : DeepSeek V3는 256 개의 신경망이있는 정교한 아키텍처를 사용하여 각 토큰 처리 작업마다 8 개를 활성화합니다. 이 접근법은 AI 교육 속도를 크게 높이고 전반적인 성능을 향상시켜 기술의 눈에 띄는 기능이됩니다.
다중 헤드 잠재주의 (MLA) :이 메커니즘은 문장의 가장 중요한 부분에 중점을 두어 주요 세부 사항을 반복적으로 추출합니다. 그렇게함으로써 MLA는 중요한 정보가 누락 될 위험을 줄여 AI가 입력 데이터의 미묘한 세부 사항을 효과적으로 캡처 할 수 있습니다.
저명한 중국 스타트 업인 Deepseek은 비교적 저렴한 비용 으로이 경쟁력있는 AI 모델을 개발했다고 주장합니다. 그들은 강력한 DeepSeek V3 Neural Network를 훈련시키는 데 6 백만 달러의 비용이 들며 2048 개의 그래픽 프로세서를 사용했다고 주장합니다.
 이미지 : ensigame.com
이미지 : ensigame.com
그러나 Semianalysis의 분석가들은 DeepSeek의 운영에는 훨씬 더 큰 계산 인프라가 필요하다는 것을 밝혀 냈습니다. 그들은 DeepSeek이 10,000 H800 단위, 10,000 H100 및 추가 H20 GPU를 포함하여 약 50,000 개의 NVIDIA HOPPER GPU를 사용하여 여러 데이터 센터에 퍼져 있다고 추정합니다. 이 자료는 AI 교육, 연구 및 재무 모델링에 사용되며, 서버에 대한 총 투자는 약 16 억 달러에 달하고 운영 비용은 9 억 9,400 만 달러입니다.
DeepSeek은 중국 헤지 펀드 하이 플라이어의 자회사로 2023 년에 별도의 AI 중심 부서로 설립했습니다. 클라우드 컴퓨팅에 의존하는 많은 스타트 업과는 달리 DeepSeek은 데이터 센터를 소유하고있어 AI 모델 최적화와 더 빠른 혁신 배포를 완전히 제어 할 수 있습니다. 회사의 자체 자금 지원 상태는 민첩성과 의사 결정 속도를 향상시킵니다.
 이미지 : ensigame.com
이미지 : ensigame.com
또한 Deepseek은 중국 최고의 대학에서 최고의 인재를 유치하며 일부 연구자들은 매년 130 만 달러 이상을 벌고 있습니다. 이러한 중대한 투자에도 불구하고,이 수치는 사전 훈련 중 GPU 사용을 설명하고 연구, 모델 개선, 데이터 처리 및 인프라와 같은 다른 실질적인 비용을 배제하기 때문에 회사의 최신 모델을 6 백만 달러에 대한 최신 모델을 훈련시킨 것에 대한 주장은 비현실적으로 보입니다.
DeepSeek은 창립 이래 AI 개발에 5 억 달러 이상을 투자했습니다. 소형 구조를 통해 더 큰 관료적 회사와 달리 AI 혁신을 빠르고 효과적으로 구현할 수 있습니다.
 이미지 : ensigame.com
이미지 : ensigame.com
DeepSeek의 예는 잘 자금을 지원하고 독립적 인 AI 회사가 업계 거인과 경쟁 할 수 있음을 보여줍니다. 회사의 성공은 상당한 투자, 기술 혁신 및 강력한 팀에 의해 주도되지만 AI 모델 개발을위한 "혁명 예산"이라는 개념은 과장 될 수 있습니다. 그럼에도 불구하고, DeepSeek의 비용은 R1의 DeepSeek의 5 백만 달러에 비해 ChatGPT4O 교육에 지출 된 1 억 달러와 같은 경쟁 업체의 비용보다 훨씬 저렴합니다.
그러나 경쟁사보다 여전히 저렴합니다.
 최신 기사
최신 기사









 최신 게임
최신 게임











