 Dom
Dom  Nawigacja
Nawigacja




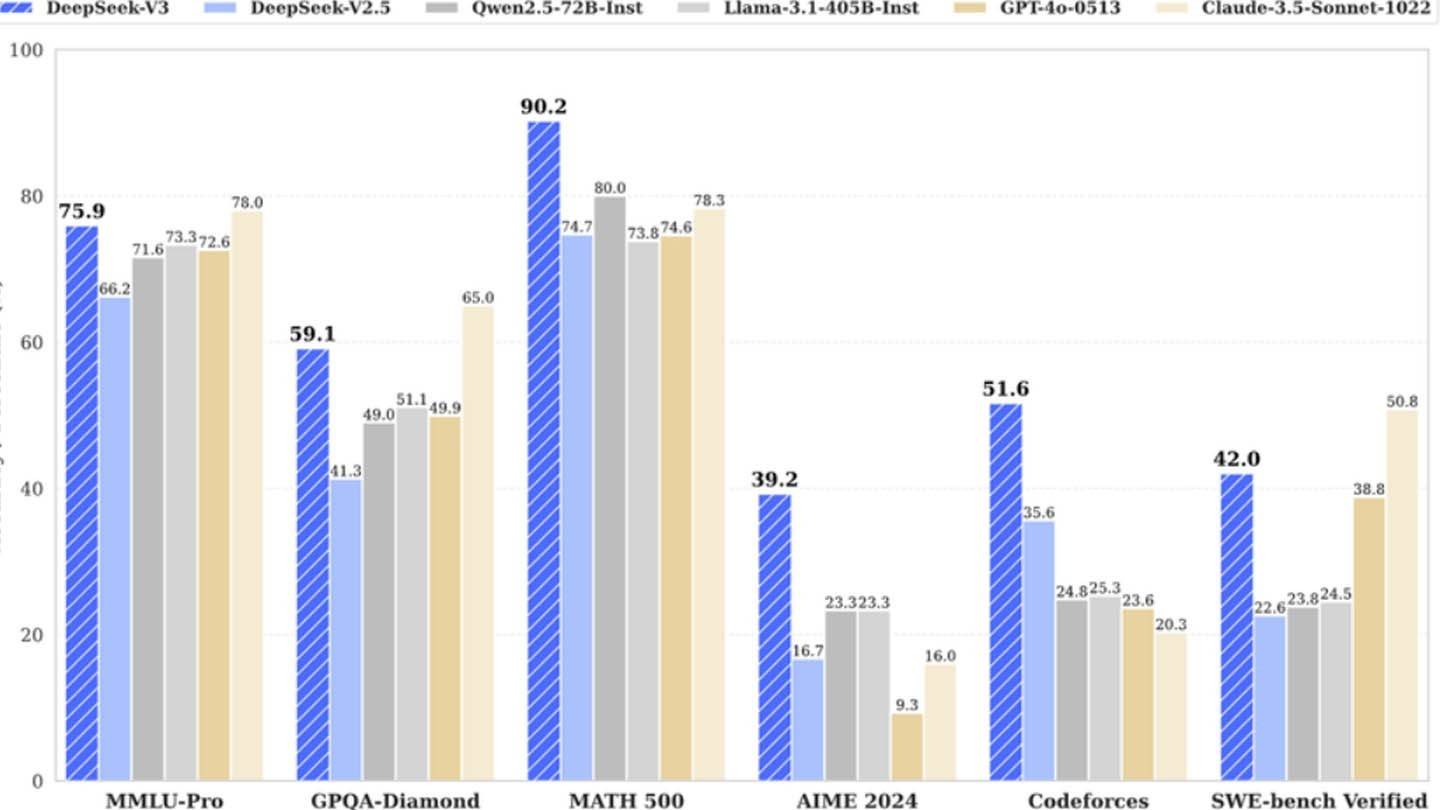
Nowy chatbot z Deepseek, który odważnie stwierdził: „Cześć, zostałam stworzona, abyś mógł zapytać o wszystko i uzyskać odpowiedź, która może cię nawet zaskoczyć”, dokonał znacznych fal w branży AI. To wprowadzenie przyciągnęło nie tylko uwagę, ale także przyczyniło się do jednego z największych spadków cen akcji NVIDIA, pokazując wpływ Deepeek na rynek.
 Zdjęcie: engame.com
Zdjęcie: engame.com
Model AI Deepseek wyróżnia się ze względu na innowacyjną architekturę i metody szkolenia. Zagłębijmy się w kluczowe technologie, które go wyróżniają:
Prognozowanie wielu tokenów (MTP) : Ta metoda pozwala modelowi przewidzieć wiele słów jednocześnie poprzez analizę różnych segmentów zdania. To nie tylko zwiększa dokładność, ale także wydajność modelu, co czyni go potężnym narzędziem do zrozumienia i generowania tekstu.
Mieszanka ekspertów (MOE) : Deepseek V3 wykorzystuje wyrafinowaną architekturę z 256 sieciami neuronowymi, aktywując osiem dla każdego zadania przetwarzania tokenu. Takie podejście znacznie przyspiesza szkolenie AI i zwiększa ogólną wydajność, co czyni go wyjątkową cechą ich technologii.
Utrzymująca uwaga wielowłócona (MLA) : Ten mechanizm koncentruje się na najważniejszych częściach zdania, wielokrotnie wydobywając kluczowe szczegóły. W ten sposób MLA zmniejsza ryzyko braku ważnych informacji, umożliwiając sztucznej inteligencji skuteczne przechwytywanie dopracowanych szczegółów w danych wejściowych.
Deepseek, wybitny chiński startup, twierdzi, że opracował ten konkurencyjny model AI po stosunkowo niskim koszcie. Twierdzą, że szkolenie potężnej sieci neuronowej Deepseek V3 kosztowało je tylko 6 milionów dolarów i wykorzystywało zaledwie 2048 procesorów graficznych.
 Zdjęcie: engame.com
Zdjęcie: engame.com
Jednak analitycy z semianalizy odkryli, że operacje Deepseek obejmują znacznie większą infrastrukturę obliczeniową. Szacują, że Deepseek wykorzystuje około 50 000 GPU Nvidia Hopper, w tym 10 000 jednostek H800, 10 000 H100 i dodatkowych GPU H20, rozprzestrzeniania się w kilku centrach danych. Zasoby te są wykorzystywane do szkolenia AI, badań i modelowania finansowego, a całkowita inwestycja firmy w serwery wynosi około 1,6 miliarda dolarów, a wydatki operacyjne w wysokości 944 milionów dolarów.
Deepseek jest spółką zależną chińskiego funduszu hedgingowego High-Flyer, która ustanowiła go jako oddzielny podział zorientowany na sztuczną inteligencję w 2023 r. W przeciwieństwie do wielu startupów, które opierają się na przetwarzaniu w chmurze, DeepSeek jest właścicielem centrów danych, zapewniając pełną kontrolę nad optymalizacją modelu AI i szybsze wdrażanie innowacji. Samofinansowany status firmy zwiększa jej zwinność i szybkość podejmowania decyzji.
 Zdjęcie: engame.com
Zdjęcie: engame.com
Ponadto Deepseek przyciąga najlepsze talenty wiodących chińskich uniwersytetów, a niektórzy badacze zarabiają ponad 1,3 miliona dolarów rocznie. Pomimo tych znaczących inwestycji roszczenie firmy o szkolenie najnowszego modelu za jedyne 6 milionów dolarów wydaje się nierealne, ponieważ liczba ta uwzględnia tylko wykorzystanie GPU podczas wstępnego treningu i wyklucza inne znaczne koszty, takie jak badania, udoskonalanie modelu, przetwarzanie danych i infrastruktura.
Od momentu założenia Deepseek zainwestował ponad 500 milionów dolarów w rozwój AI. Jego kompaktowa struktura pozwala mu szybko i skutecznie wdrażać innowacje AI, w przeciwieństwie do większych, bardziej biurokratycznych firm.
 Zdjęcie: engame.com
Zdjęcie: engame.com
Przykład Deepseek ilustruje, że dobrze finansowana, niezależna firma AI może konkurować z gigantami branżowymi. Podczas gdy sukces firmy wynika z znacznych inwestycji, przełomów technicznych i silnym zespołem, pojęcie „rewolucyjnego budżetu” dla opracowywania modelu AI może być zawyżone. Niemniej jednak koszty Deepseek pozostają znacznie niższe niż koszty jego konkurentów, takich jak 100 milionów dolarów wydanych na szkolenie Chatgpt4o w porównaniu z 5 milionami dolarów Deepseek za R1.
Jest jednak nadal tańszy niż jego konkurenci.
 Najnowsze artykuły
Najnowsze artykuły









 Najnowsze gry
Najnowsze gry










