 首頁
首頁  導航
導航




DeepSeek的新聊天機器人大膽地說:“嗨,我是被創建的,所以您可以問任何東西並獲得一個甚至可能使您感到驚訝的答案,” AI行業引起了重要的浪潮。這次介紹不僅引起了人們的關注,而且促成了NVIDIA最大的股票價格下跌之一,從而展示了DeepSeek對市場的影響。
 圖片:ensigame.com
圖片:ensigame.com
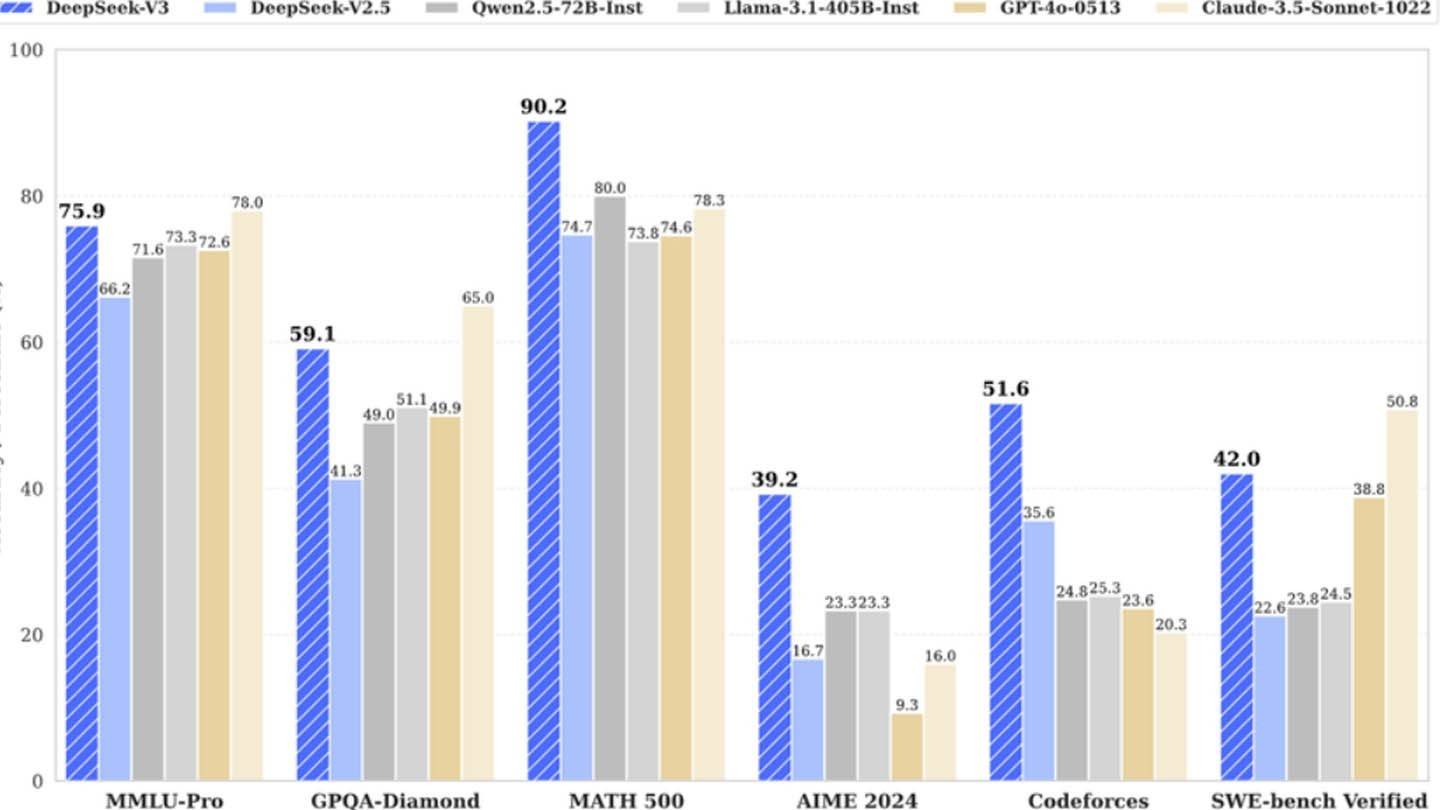
DeepSeek的AI模型由於其創新的建築和培訓方法而脫穎而出。讓我們深入研究將其與眾不同的關鍵技術:
多語預測(MTP) :此方法允許模型通過分析句子的不同段立即預測多個單詞。這不僅提高了模型的準確性,而且可以提高模型的效率,從而成為理解和生成文本的強大工具。
專家的混合物(MOE) :DeepSeek V3使用了具有256個神經網絡的複雜體系結構,每個令牌處理任務都激活了8個。這種方法可大大加快AI訓練並提高整體性能,從而成為其技術的出色功能。
多頭潛在註意力(MLA) :這種機制著重於句子的最關鍵部分,重複提取關鍵細節。通過這樣做,MLA降低了丟失重要信息的風險,使AI可以有效地捕獲輸入數據中的細微細節。
著名的中國初創公司DeepSeek聲稱已經以相對較低的成本開發了這種競爭性的AI模型。他們斷言,培訓強大的DeepSeek V3神經網絡僅花費了600萬美元,僅使用了2048個圖形處理器。
 圖片:ensigame.com
圖片:ensigame.com
但是,半分析的分析師發現了DeepSeek的操作涉及更大的計算基礎架構。他們估計DeepSeek使用了大約50,000個NVIDIA HOPPER GPU,其中包括10,000 h800單元,10,000 H100和其他H20 GPU,分佈在幾個數據中心。這些資源用於AI培訓,研究和財務建模,該公司對服務器的總投資達到16億美元,運營費用為9.44億美元。
DeepSeek是中國對沖基金高飛行員的子公司,該基金在2023年將其確立為以AI為中心的單獨的部門。與許多依靠雲計算的初創公司不同,DeepSeek擁有其數據中心,使其完全控制了AI模型優化和更快的創新部署。該公司的自籌資金地位提高了其敏捷性和決策速度。
 圖片:ensigame.com
圖片:ensigame.com
此外,DeepSeek吸引了領先的中國大學的頂尖人才,一些研究人員每年收入超過130萬美元。儘管有這些重大投資,但該公司要求以600萬美元的價格培訓其最新模式的主張似乎是不現實的,因為該數字僅在培訓期間佔用GPU使用,並排除了其他實質性成本,例如研究,改進,數據處理和基礎架構。
自成立以來,DeepSeek已為AI開發投資了超過5億美元。它的緊湊結構使其能夠與更大,更官僚的公司不同,可以快速有效地實施AI創新。
 圖片:ensigame.com
圖片:ensigame.com
DeepSeek的例子表明,一家資金充足的獨立AI公司可以與行業巨頭競爭。儘管公司的成功是由大量投資,技術突破和強大的團隊驅動的,但AI模型開發的“革命預算”的概念可能被誇大了。儘管如此,DeepSeek的成本仍大大低於其競爭對手的費用,例如在培訓ChatGpt4O上花費的1億美元,而DeepSeek的R1 $ 500萬。
但是,它仍然比競爭對手便宜。
 最新文章
最新文章









 最新遊戲
最新遊戲











