 Дом
Дом  Навигация
Навигация




Новый чат -бот из DeepSeek, который смело заявил: «Привет, я был создан, чтобы вы могли спросить что угодно и получить ответ, который может даже удивить вас», вызвал значительные волны в индустрии ИИ. Это введение не только привлекло внимание, но и способствовало одному из крупнейших падений цен на акции Nvidia, демонстрируя влияние Deepseek на рынок.
 Изображение: Ensigame.com
Изображение: Ensigame.com
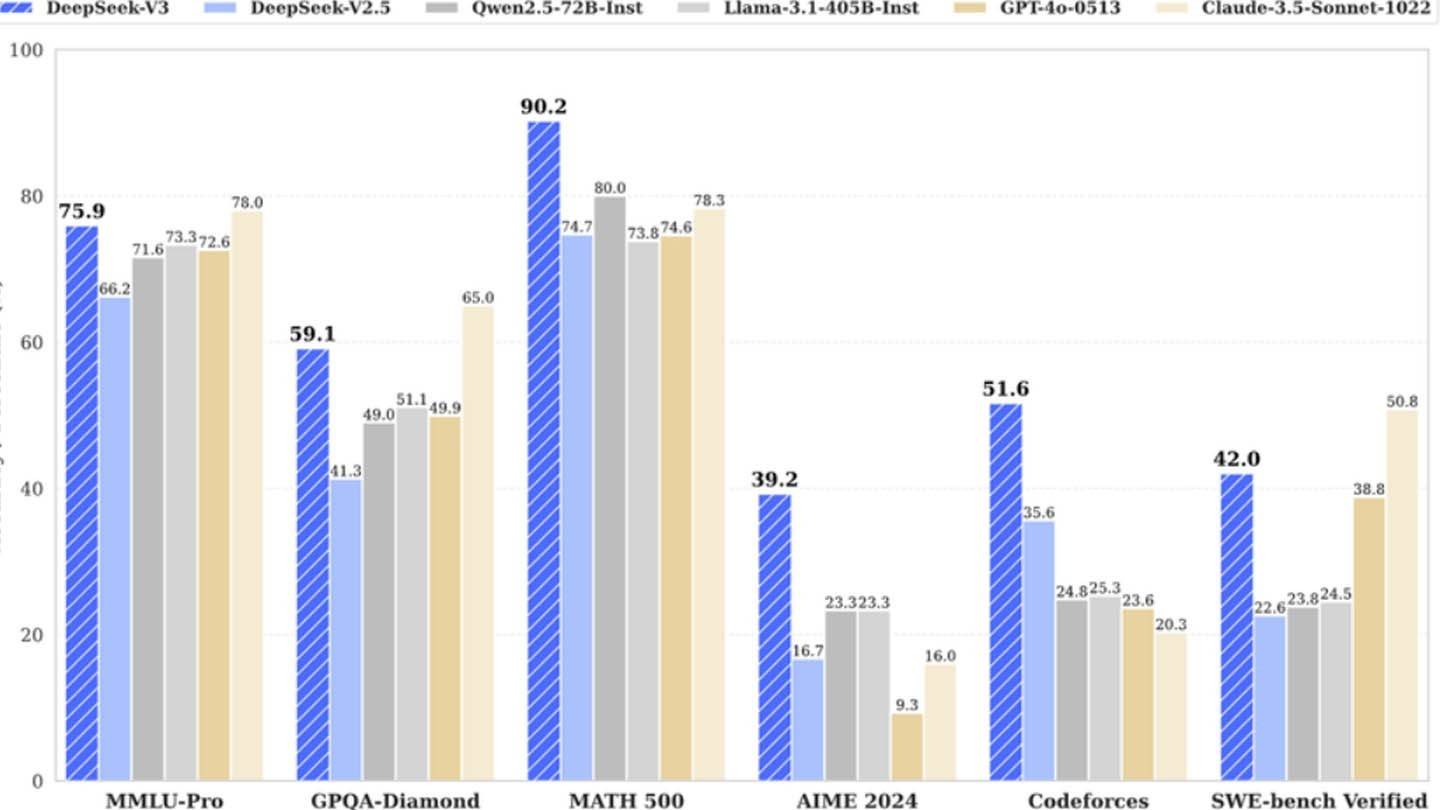
Модель AI DeepSeek выделяется благодаря своей инновационной архитектуре и методам обучения. Давайте углубимся в ключевые технологии, которые выделяют их:
Multi-Token Production (MTP) : этот метод позволяет модели прогнозировать несколько слов одновременно, анализируя различные сегменты предложения. Это не только повышает точность, но и эффективность модели, что делает ее мощным инструментом для понимания и создания текста.
Смесь экспертов (MOE) : DeepSeek V3 использует сложную архитектуру с 256 нейронными сетями, активируя восемь для каждой задачи обработки токенов. Этот подход значительно ускоряет обучение ИИ и повышает общую производительность, что делает его выдающейся особенностью их технологии.
Многопользовательское скрытое внимание (MLA) : этот механизм фокусируется на самых важных частях предложения, неоднократно извлекая ключевые детали. Таким образом, MLA снижает риск отсутствия важной информации, позволяя ИИ эффективно захватывать детализацию в входных данных.
DeepSeek, известный китайский стартап, утверждает, что разработал эту конкурентную модель ИИ по относительно низкой стоимости. Они утверждают, что обучение мощной нейронной сети Deepseek V3 стоит им всего 6 миллионов долларов и использовал только 2048 графических процессоров.
 Изображение: Ensigame.com
Изображение: Ensigame.com
Тем не менее, аналитики полуанализа обнаружили, что операции Deepseek включают в себя гораздо большую вычислительную инфраструктуру. Они оценивают, что Deepseek использует около 50 000 графических процессоров Nvidia Hopper, в том числе 10 000 единиц H800, 10 000 H100 и дополнительных графических процессоров H20, распространяющиеся по нескольким центрам обработки данных. Эти ресурсы используются для обучения, исследований и финансового моделирования искусственного интеллекта, а общие инвестиции компании в серверы достигают около 1,6 миллиарда долларов, а эксплуатационные расходы - 944 миллиона долларов.
DeepSeek является дочерней компанией китайского хедж-фонда, который установил его как отдельное подразделение, ориентированное на AI в 2023 году. В отличие от многих стартапов, которые полагаются на облачные вычисления, DeepSeek владеет своими центрами обработки данных, что дает ему полный контроль над оптимизацией модели искусственного интеллекта и более быстрое внедрение инноваций. Самофинансируемый статус компании повышает его гибкость и скорость принятия решений.
 Изображение: Ensigame.com
Изображение: Ensigame.com
Кроме того, Deepseek привлекает лучших талантов от ведущих китайских университетов, а некоторые исследователи зарабатывают более 1,3 миллиона долларов в год. Несмотря на эти значительные инвестиции, утверждение компании о обучении своей последней модели всего за 6 миллионов долларов кажется нереальной, поскольку на этой цифре учитывается только использование графических процессоров во время предварительного обучения и исключает другие существенные затраты, такие как исследования, уточнение модели, обработка данных и инфраструктура.
С момента своего основания DeepSeek инвестировал более 500 миллионов долларов в разработку ИИ. Его компактная структура позволяет ему быстро и эффективно внедрять инновации искусственного интеллекта, в отличие от более крупных, более бюрократических компаний.
 Изображение: Ensigame.com
Изображение: Ensigame.com
Пример DeepSeek иллюстрирует, что хорошо финансируемая независимая компания по искусству может конкурировать с отраслевыми гигантами. В то время как успех компании обусловлено существенными инвестициями, техническими прорывами и сильной командой, понятие «революционного бюджета» для разработки модели искусственного интеллекта может быть переоценен. Тем не менее, затраты DeepSeek остаются значительно ниже, чем у его конкурентов, таких как 100 миллионов долларов, потраченных на обучение CHATGPT4O по сравнению с 5 миллионами долларов США за R1.
Тем не менее, это все еще дешевле, чем его конкуренты.
 Последние статьи
Последние статьи









 Последние игры
Последние игры











